Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Contents
- Prerequisite
- Introduction
- Experimental Setup
- Ground truth Matters Little
- Why does In-Context Learning work?
- Conclusion
Prerequisite
In-context learning
In-context learning(ICL) means that the model understands the contextual meaning within a prompt and generates responses based on it. In other words, ICL does not involve updating the model's weights, like in pretraining or fine-tuning, and it does not require a separate model training process. ICL's approach mirrors the human cognitive reasoning process, making it a more intuitive model for problem-solving.

ICL can be divided into zero-shot, one-shot, and few-shot depending on the given context and examples.
Zero-shot
Zero-shot refers to the ability to perform a task without any given examples.
GPT: "pomme rouge"
One-shot
One-shot refers to performing a task with the help of a single example.
Then what is the green watermelon.
GPT: "vert watermelon"
Few-shot
Few-shot learning refers to performing a task with the help of multiple examples.
Then what is the 'green apple'?
GPT: "vert Apple"
Introduction
In-context learning is a useful method to improve a model's performance without additional training. However, despite this performance improvement, there is little understanding of how it works and which aspects of the demonstrations contribute to end task performance.
This paper investigates how the model learns and which elements of the demonstration impact the performance of downstream tasks. The goal and conclusion of this research are as follows:
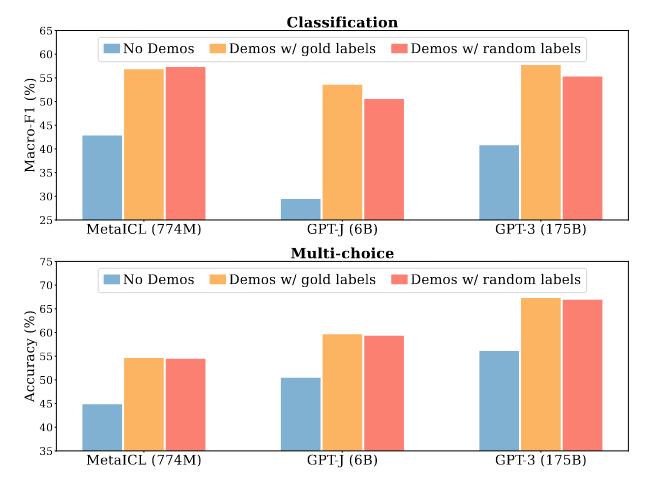
- Evaluate the importance of ground-truth labels in demonstrations: replacing the labels in demonstrations with random labels barely hurts performance in a range of classification and multi-choice tasks.
- Identify key factors in demonstration contributing to ICL: Label space, the distribution of the input text and format.
The example of random labels
Label: "Negative"
Experimental Setup
In this study, 6 language models with two inference methods, direct and channel, were used. Direct method means that the model's input is in the usual order and predicts the output corresponding to the input. But channel method means that the model is given the output first and then predicts the input.
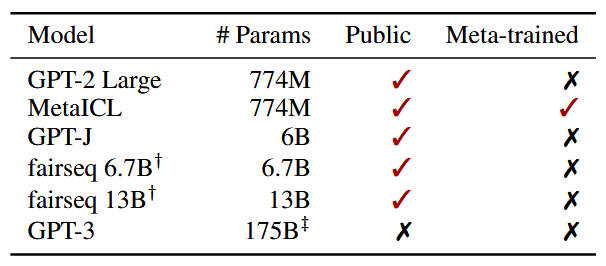
The evaluation was conducted on 26 datasets, that cover various tasks and domains. (e.g. classification and multichoice)
Ground Truth Matters Little
To figure out the importance of correctly-paired inputs and lables in the demonstrations, the researcher compared the three methods
- No demonstrations: typical zero-shot method, i.e., $argmax_{y \in C} P(y|x)$
- Demonstrations w/ gold labels: typical ICL method (correct input-label mapping), i.e., $argmax_{y \in C} P(y|x_1, y_1, …, x_k, y_k, x)$
- Demonstrations w/ random labels: alter gold labels from the labeled data to random labels, i.e., $argmax_{y \in C} P(y|x_1, \tilde{y_1}, …, x_k,\tilde{y_k}, x)$

Results are reported above figure. Without demonstrations, the model's performance significantly decrease. However, the trend is that replacing gold labels with random labels only marginally hurts performance. This indicates that models are capable of recovering the expected input-label correspondence for the task; but, it is not directly from the pairings in the demonstrations.
Why does In-Context Learning work?
Above shows that golden input-label mapping is not a crucial role in demonstrations. Then which aspects of the demonstrations improve the model performance?
The researcher define three aditional asoects of the demonstrations that potentially provide learning signal
- The distribution of the input text : the underlying distribution of the input text ($x_1 … x_k$) in the demonstrations
- The label space : the space covered by $y_1 .. y_k$
- The format : the use of input-label pairing as the format

Impact of the distribution of the input text
The researcher compared the performance of the model with out-of-distribution (OOD) demonstrations while keeping the label space and the format. The results show that the model's performance is significantly affected by the distribution of the input text.
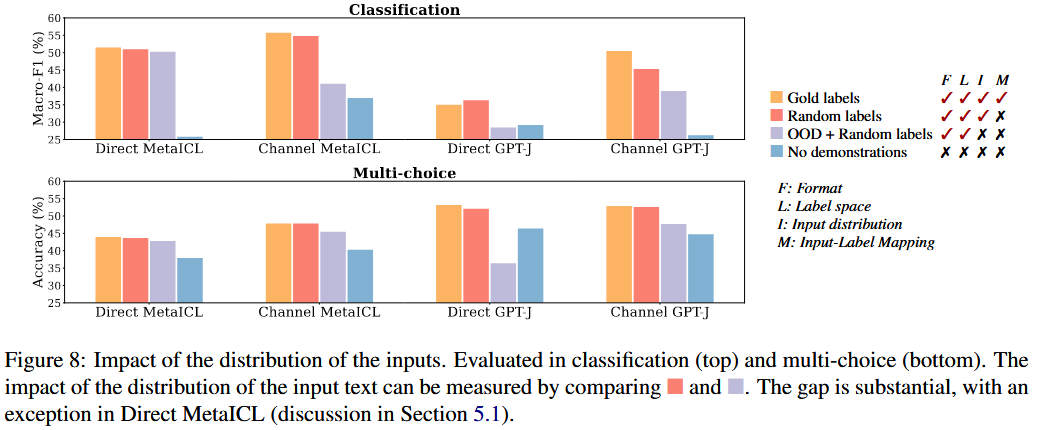
This shows that in-distribution inputs impact the performance of model due to conditioning on the in-distribution text making the task closer.
Impact of the label space
In this experiment, researcher used random English words as labels for all k pairs. They construct a random subset of English words $|C_{rand}| = |C|$ and randomly pair $\tilde{y_i} \in C_{rand}$ with $x_i$
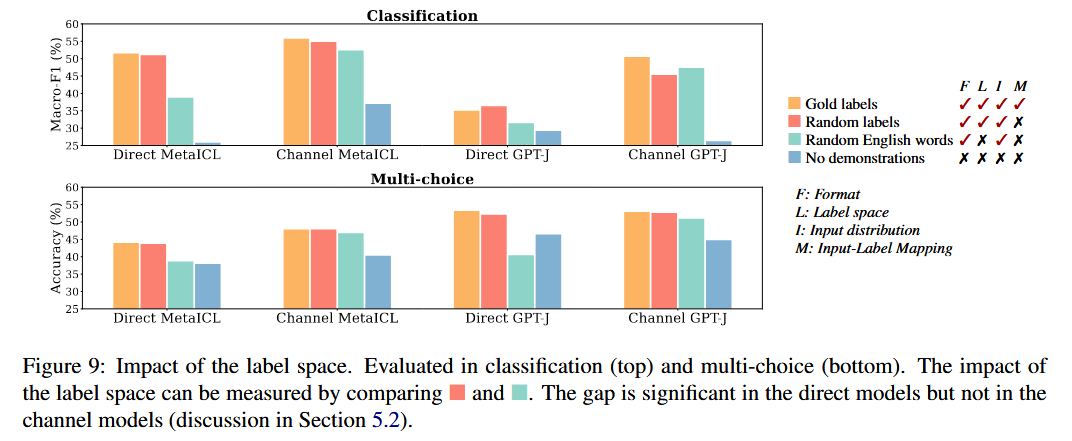
Along with above results, the channel models does not show significant drop or sometimes even an increase. This is because the channel models only condition on the labels. However, the direct models exhibits the performance gap. This indicates that they learn the distribution of the label space for a given input.
Impact of the format
The "format" means the use of input-label pairing. Experiments were conducted by changing the format using methods such as demonstrations with no labels and demonstrations with labels only.
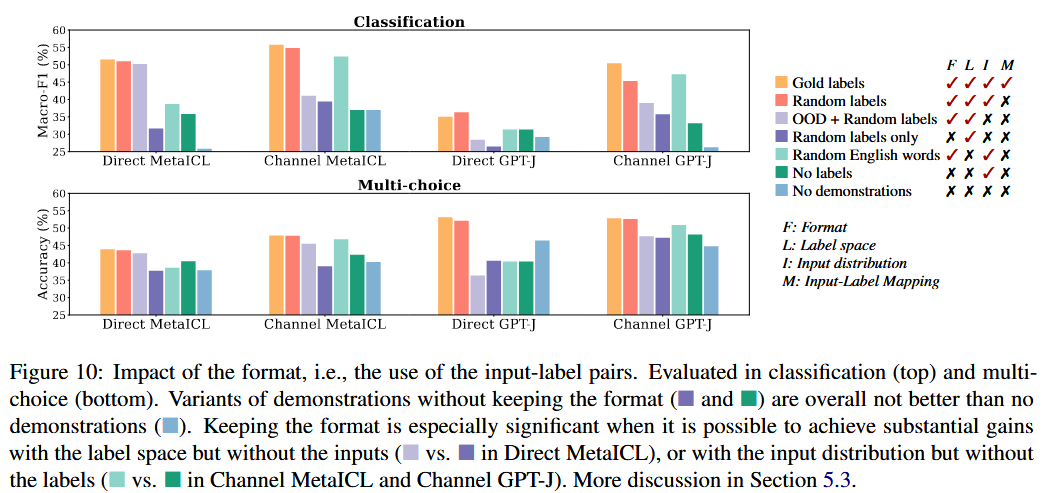
As shown in the figure above, altering the format (indicated by the purple and green bars) led to performance that was nearly the same or even lower than the no-demonstration case. This suggests that format is essential in guiding the model to replicate the intended inference process.
Impact of the meta-training
MetaICL is minimally affected by random labels; however, changes in format—whether using only random labels or no labels at all—significantly impact performance. This suggests that meta-training emphasizes learning straightforward elements, like format, over correctly matched input-label examples from demonstrations, implying that format may be easier for the model to leverage. Additionally, altering the output space (e.g., using random English words) has little effect on Channel MetaICL compared to Direct MetaICL. This implies that utilizing the input text space the model needs to generate is simpler than utilizing the input text space the model relies on for conditioning.
The example demonstrations used in identifying the aspect of the demonstration

Conclusion
- Format Matters More Than Labels: The study shows that correct input-label pairings are less critical than maintaining a consistent format in demonstrations. Random labels have minimal impact, but format changes significantly reduce performance, highlighting format as a primary cue for the model.
- MetaICL Leverages Simple Patterns: MetaICL focuses on simple elements like format rather than precise input-label matching, making format an easily exploitable structure for In-Context Learning.
- Exploiting Input Structure Over Correctness: The findings suggest that when optimizing In-Context Learning, designing demonstrations with clear structural hints may be more beneficial than ensuring perfect labels.